January 9, 2025 / Nirav Shah
Amazon SageMaker is a fully managed service provided by Amazon Web Services (AWS) that enables developers and data scientists/analysts to build, train, and deploy machine learning models at scale.
The prerequisites include gaining an understanding of how AWS works with S3, IAM, and SageMaker. Below is very first screen after login to AWS and open SageMaker
After the notebook was created, a modification was made in the IAM settings, where a custom S3 bucket was specified for storing all of the data.
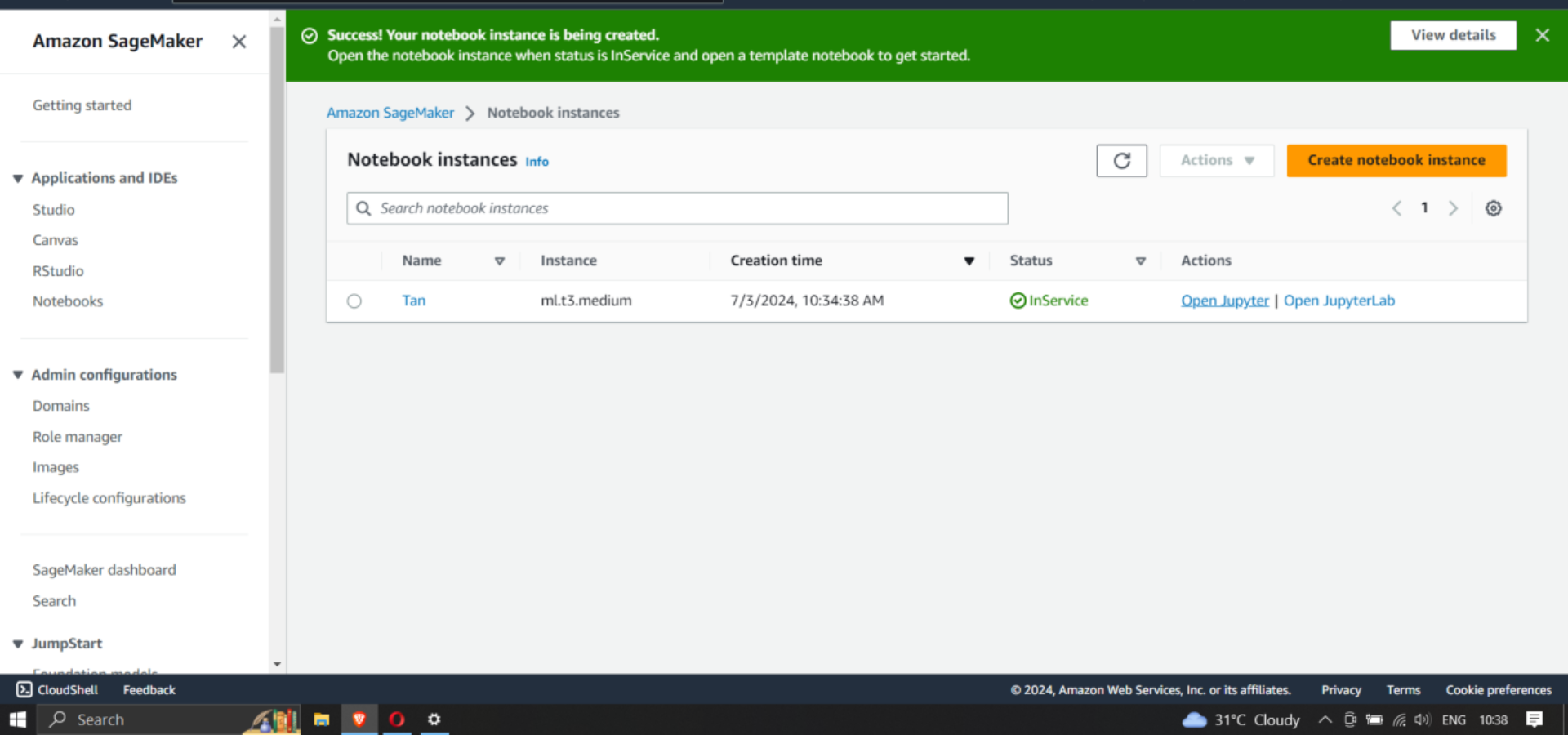
Once the notebook is created and its status is set to InService, the Jupyter option is accessible, where the code for the model could be written.
For better understanding, let’s consider an example using a dataset of income for a specific age group.
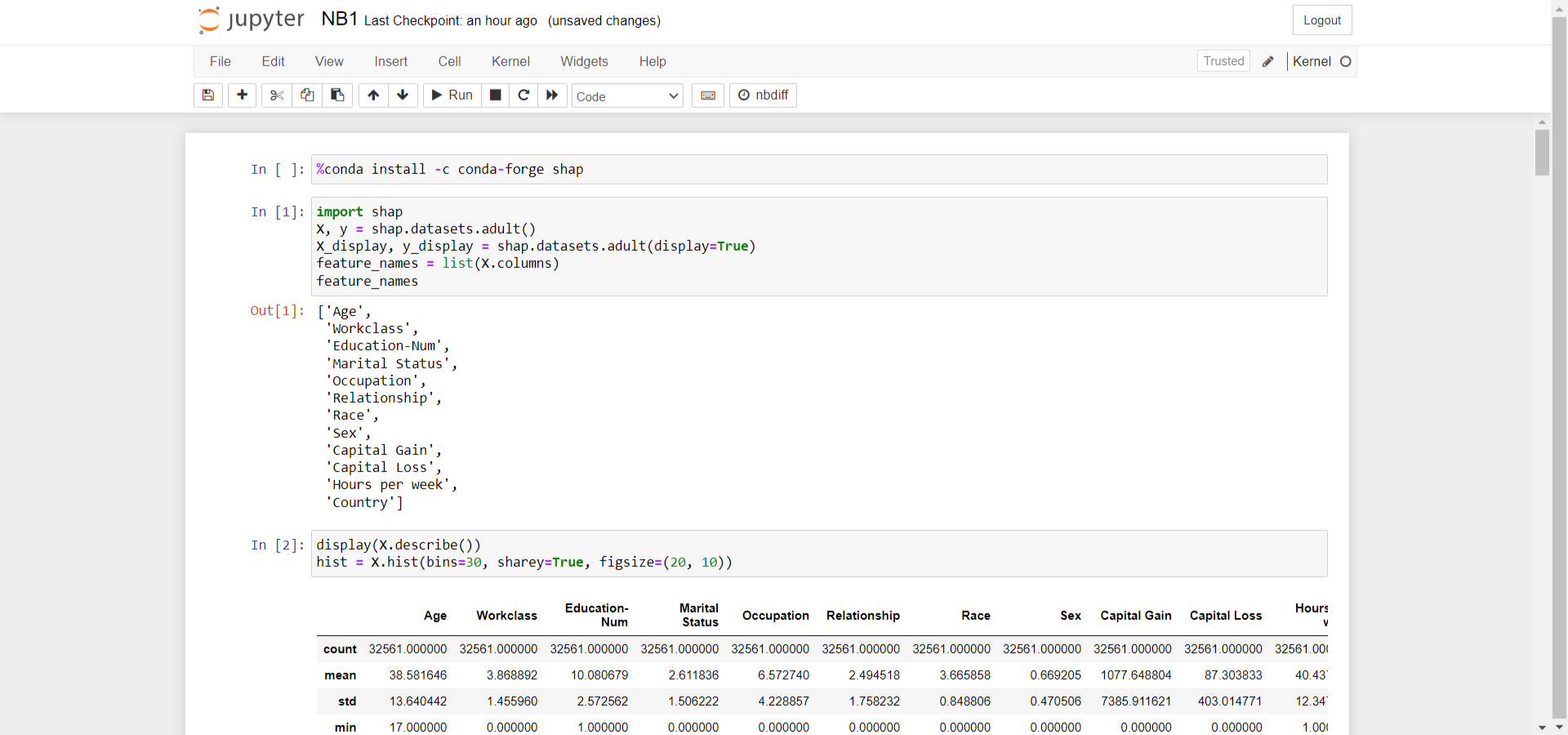
Moving on to exploring this dataset, we first wrote a code that displayed its features, revealing fields such as name, age, etc. After that, additional code was written to extract more information.
The next step is the statistical overview of the datasets and its histograms to get more detail about the dataset to make the visualisation easier.
After the data was visualized, a split was performed into training, validation, and test datasets. The dataset was divided, with 75% allocated to the training set and the remaining to the validation set. Following this process, the Pandas package was used to align each dataset by concatenating the numeric features with the true labels. Afterward, the set was checked to ensure that everything had worked correctly.
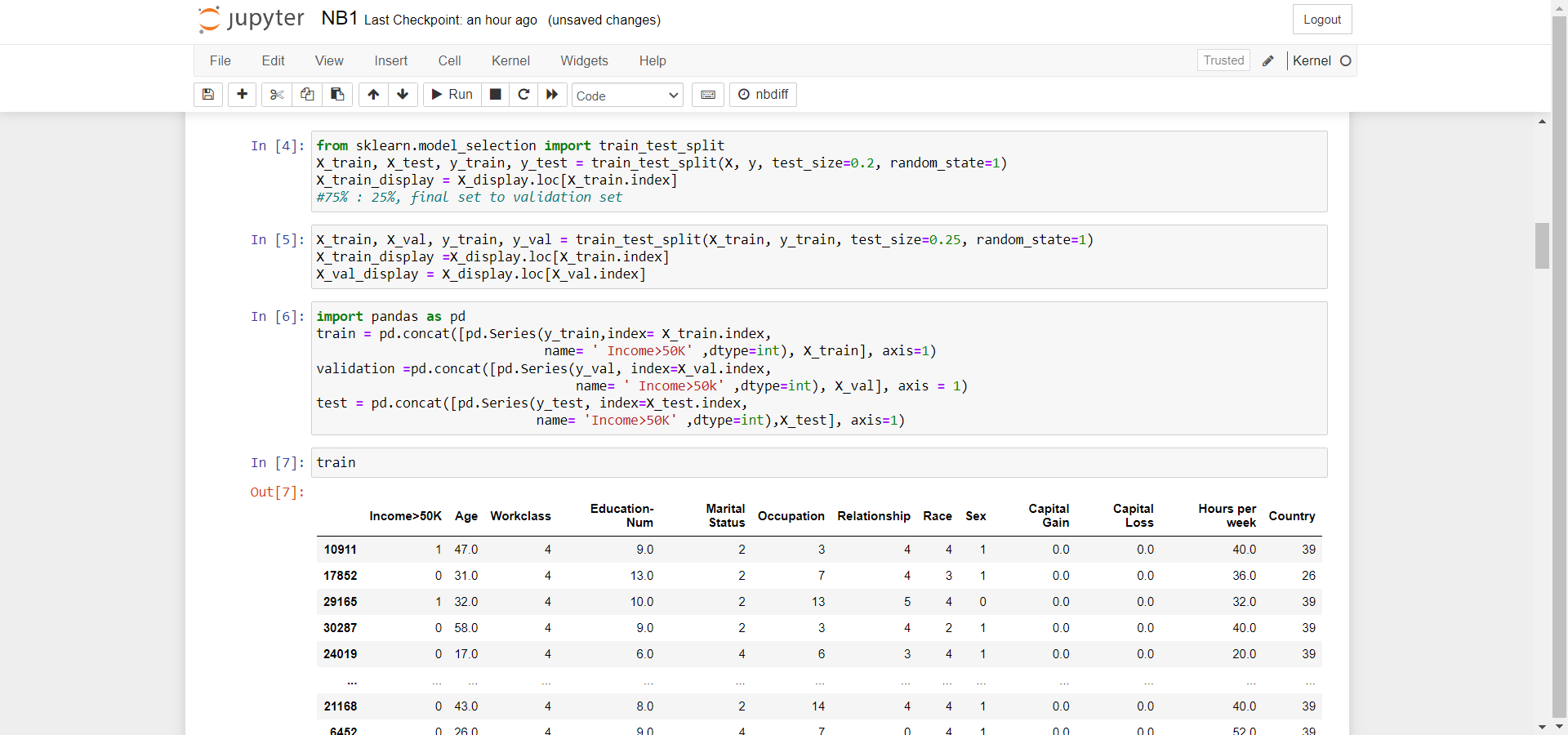
Following this process, the training and validation datasets were converted into CSV files, ensuring both datasets matched the input file format required for the XGBoost algorithm (which is discussed later)
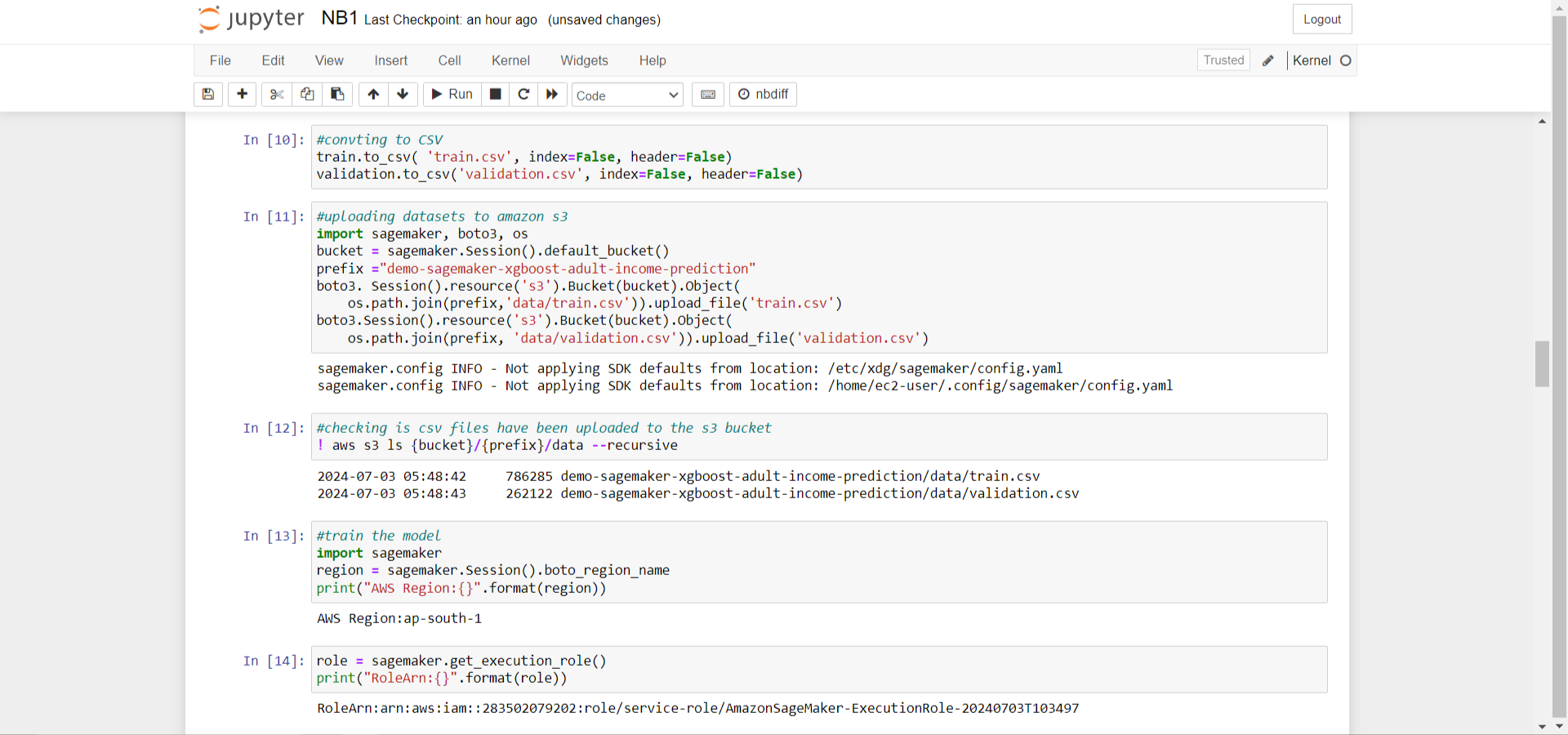
The datasets were uploaded into Amazon S3, where that would be utilized by a compute-optimized SageMaker instance on Amazon EC2 for training. Amazon Elastic Compute Cloud (Amazon EC2) is a service that provides resizable compute capacity in the cloud. Finally, code was written to run the AWS CLI to verify whether the files had been uploaded to the S3 bucket.
It time to train model now. To simplify the process, the built-in XGBoost algorithm in Amazon SageMaker was used. This approach was chosen to streamline pre-evaluating different models and determining which one best suited the dataset.
Next, the AWS region and the execution role ARN (Amazon Resource Name) used by SageMaker were retrieved and printed. Following this, a SageMaker estimator was constructed. Several parameters were specified, including an image URI container, a role (the AWS Identity and Access Management role used by SageMaker to perform tasks on behalf of the user), a training instance count, a training instance type (to define the Amazon EC2 ML compute instances used for training), a training volume size, and an output path to the S3 bucket.
Subsequently, the parameters for the XGBoost algorithm were configured by calling the set_hyperparameters method of the estimator, ensuring the model was tuned for better optimization
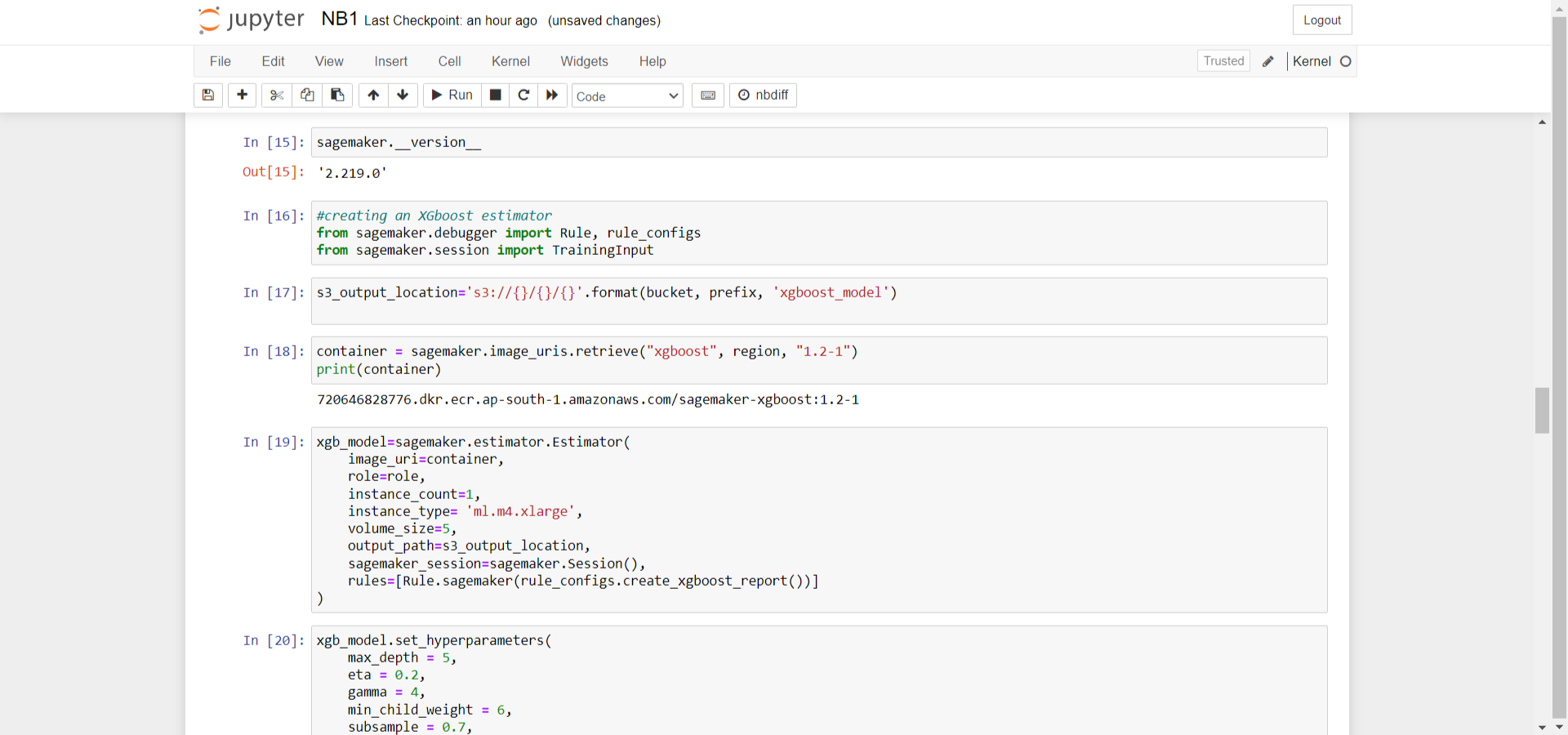
Once all the parameters were configured, a block of code was written to set up the training input objects, utilizing the training and validation datasets that had been previously uploaded to Amazon S3 during the dataset splitting process.
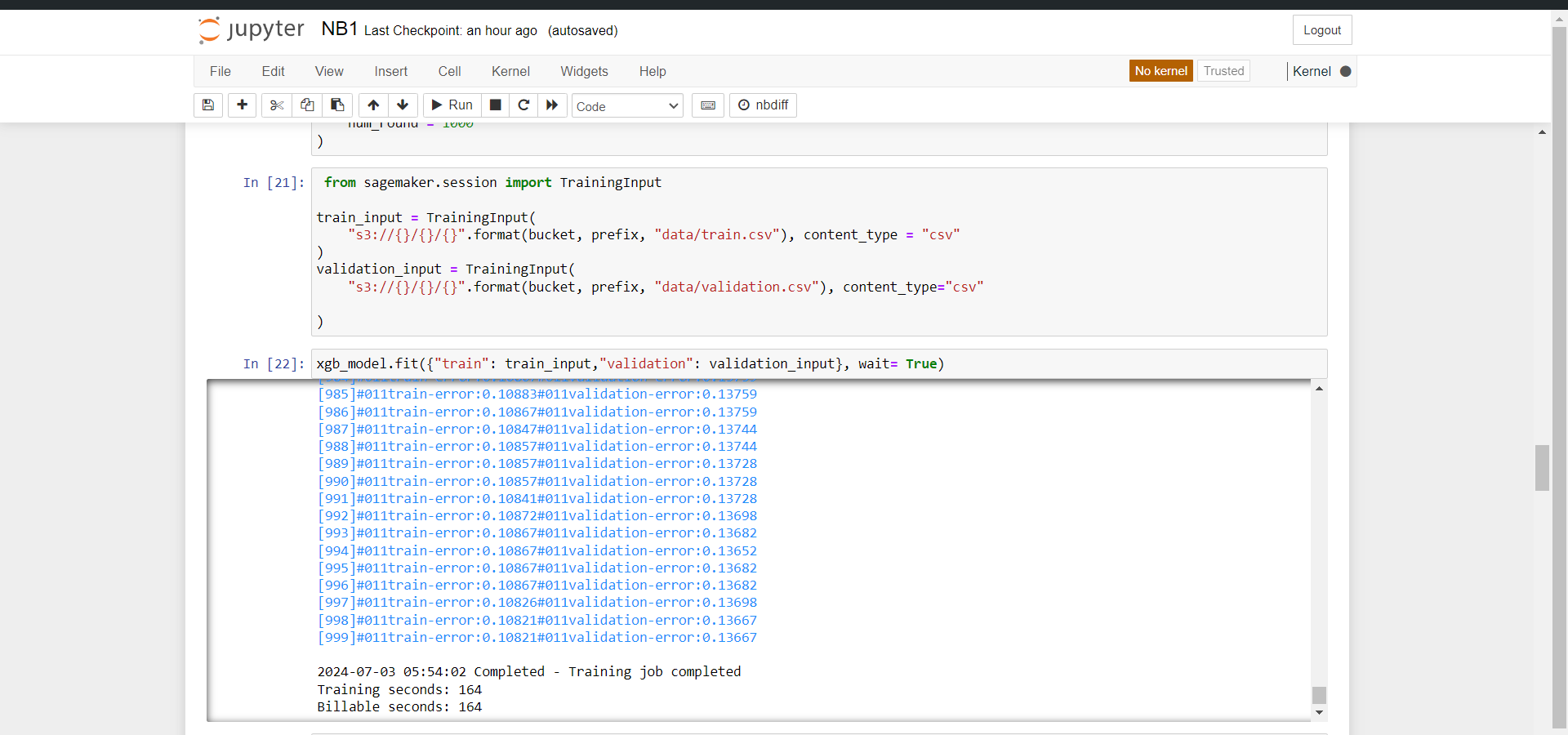
After completing the configuration, the model was trained using the fit method. This method displayed progress logs and waited until the training process was complete. Finally, it provided details about the training duration, including the total training seconds and the billable seconds.
After completing that process, a block of code was written to specify the S3 bucket URI where the debugger training reports are generated and to verify whether the reports exist.
Once this step was completed, an IPython script was created to retrieve the file link for the XGBoost training report. This report provides detailed summaries and insights, including information about the EC2 instance, resource utilization, system bottleneck detection results, and Python operation profiling results..
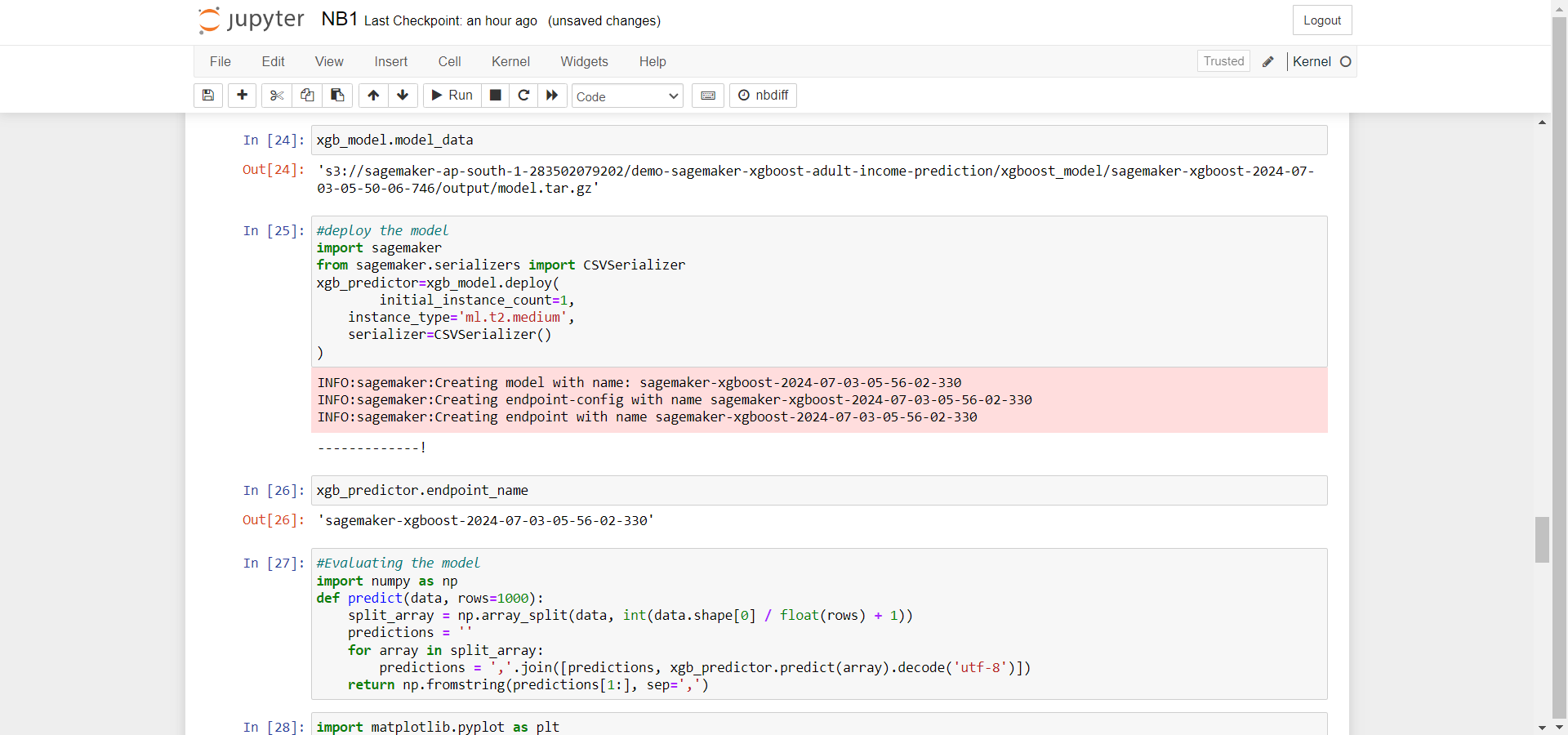
After the completion of the above steps,Next, the process moved on to deploying the model on Amazon EC2 using Amazon SageMaker through the deploy method of the XGBoost model.
Three key parameters were specified during deployment:
1. Initial Instance Count – Defines the number of instances to deploy the model.
2. Instance Type – Specifies the type of instances to be used for running the deployed model.
3. Serializer – Converts input data from various formats into a CSV-formatted string.
After completing the deployment, the name of the endpoint generated by the deploy method was retrieved.
The final step involved evaluating the model to ensure it could make accurate predictions based on the provided data. In other words, this step was conducted to test the model’s accuracy.
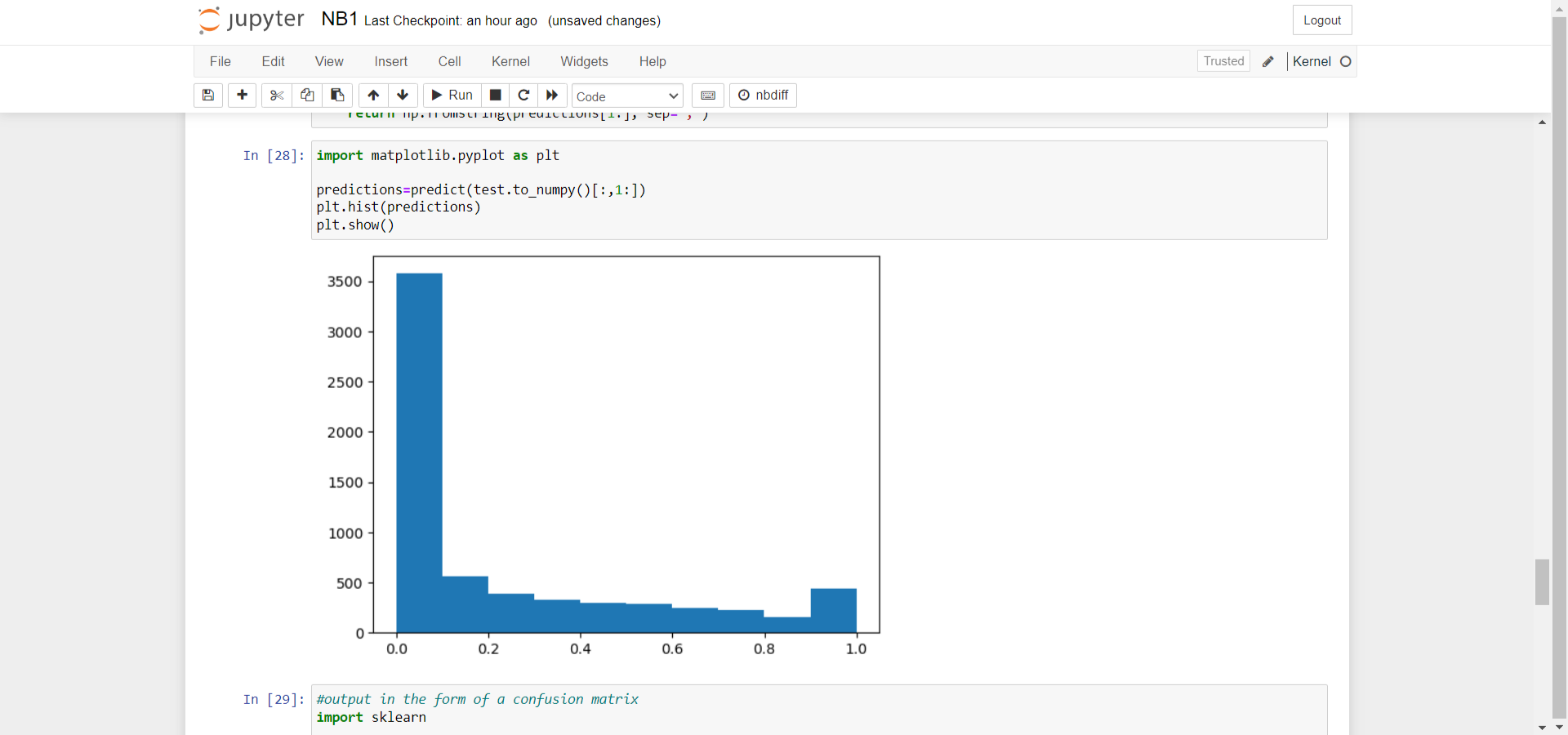
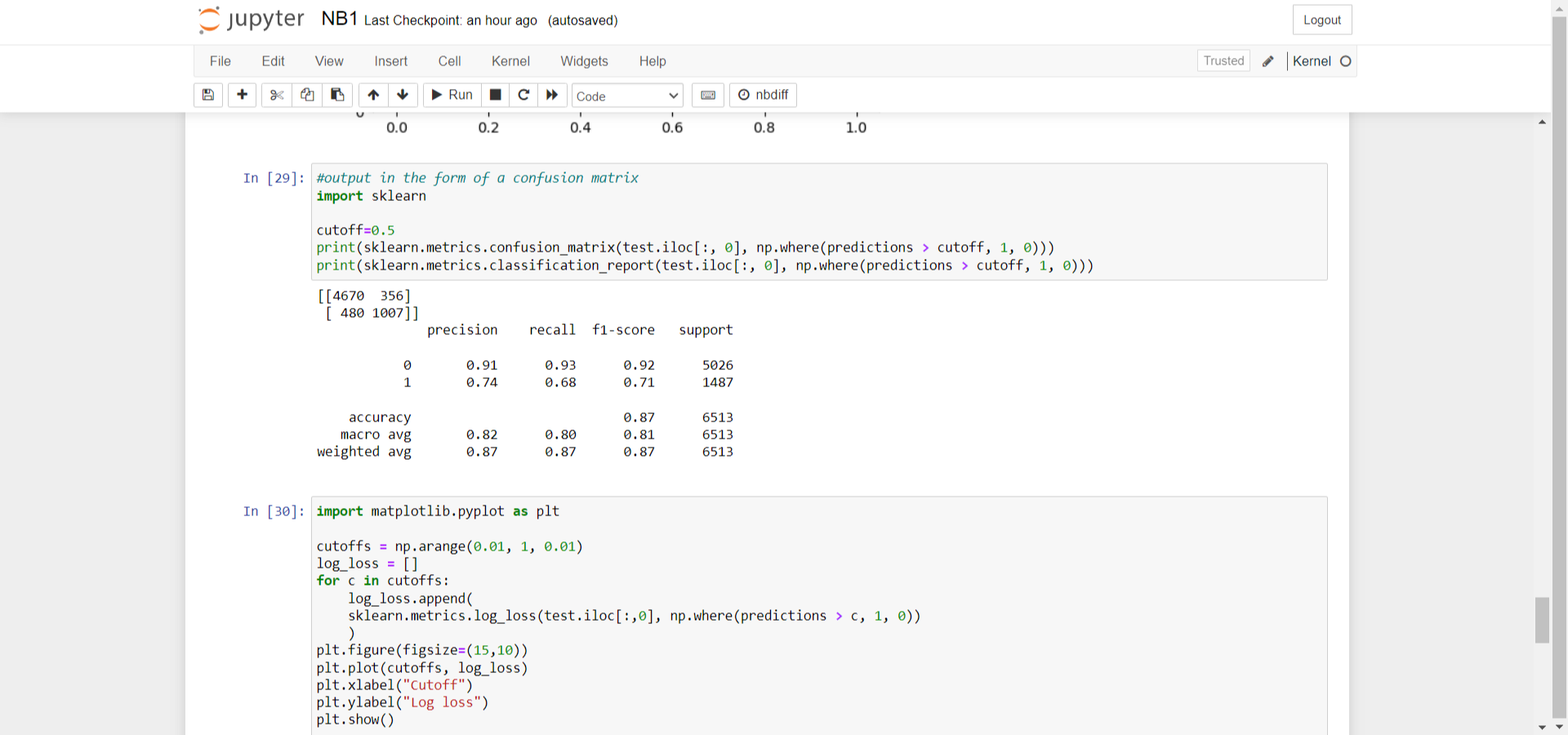
For visualization, NumPy and Matplotlib were used to generate graphs and charts, providing a clear representation of the output data. Additionally, Scikit-learn was utilized to generate a confusion matrix, offering insights into the model’s accuracy.
In this case, the model achieved an overall accuracy of 87%. Finally, a log-loss graph was plotted using Matplotlib, which highlighted the minimum log-loss value and its cutoff point.


Nirav Shah is the Director of Eternal Web Pvt Ltd, an AWS Advanced Consulting Partner and certified Odoo Partner based in the UK. With over a decade of experience in cloud computing, digital transformation, and ERP implementation, Nirav helps enterprises adopt the right technology to solve complex business challenges. He specialises in AWS infrastructure, Odoo ERP, and web development solutions for businesses across the UK and beyond.
Have queries about your project idea or concept? Please drop in your project details to discuss with our AWS Global Cloud Infrastructure service specialists and consultants.